
Minimal Hunyuan workflow for RTX 3060 (8gb vram)版本v1.0 (ID: 1293220)
This is smallest workflow I could run on my RTX 3060 under Ubuntu 24.04.1 and 32gb RAM. Let me know if that worked for you.
描述: minimal workflow to create a...

V2.01 - Janky Lightning TURBO Text 2.01 Video Hunyuan - cuts rendering time significantly (redownload. 2 had default broken issues)版本v1.0 (ID: 1293883)
Your milage may vary: for some, 33% increase, others have said no real significant change. There are other methods now coming into play that are helping tweak things, (wavespee...
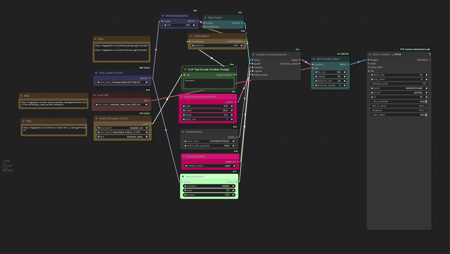
Fast Hunyuan Video (GGUF) T2V版本T2V FastHunyuan (GGUF) (GGUF)
This is the Text to Video version of the fast Hunyuan Video (GGUF). With the fast model I used on this it was using about 14gigs of vram. I am on a RTX 4090.On the workflow I p...

Hunyuan V2V Flow Edit版本v1.0 (ID: 1302204)
idea from this reddit: https://www.reddit.com/r/StableDiffusion/comments/1i4fkuk/hunyuan_vid2vid/custom node:https://github.com/logtd/ComfyUI-HunyuanLoomlora used in example:ht...
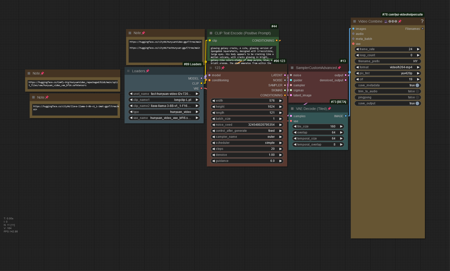
Fast Hunyuan Video (GGUF) T2V版本T2VFHUN(GGUF)1 (ID: 1286931)
This is the Text to Video version of the fast Hunyuan Video (GGUF). With the fast model I used on this it was using about 14gigs of vram. I am on a RTX 4090.On the workflow I p...
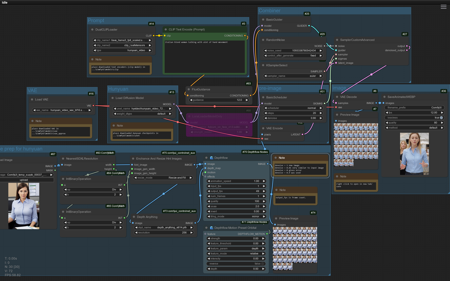
ComfyUI Hunyuan image to video using LoRAs版本v1.0 (ID: 1301642)
image to video using Hunyuan checkpoint.32GB ram and 16GB vram/laptop 3080TI.
描述:
训练词语:
...

ULTRA DETAILER - Detail Daemon + Upscale + ADetailer版本v2 (ID: 1303861)
Tired of boring images without details?This workflow combines power of Detail Daemon, Upscaling and ADetailer to add details to your imageAvailable on:TensorArt: https://tensor...

FooocusExtend版本v8 (ID: 1302876)
I would like to share my version of the original Fooocus (developed by lllyasviel) - FooocusExtend (https://github.com/shaitanzx/Fooocus_extend)You can also run it through Goog...

Hunyuan | T2V | Upscale + Interpolation版本v1.0 (ID: 1284165)
A workflow for Hunyuan video.After initial (lowres) video generation, you can enable the upscaler and interpolation for 1080p. Should work well with 12GB of VRAM.
...

Seamless 360° Flux Comfyui Workflow版本v1.0 (ID: 1287300)
The workflow can generate seamless 360° VR images using the Flux models Fast and Fill.The images can be viewed in a VR headset or a web-based 360° image viewer.LoRA:https://civ...

Cosmos AUTOMATED Image to Video (I2V) - EnragedAntelope版本v1.0 (ID: 1287795)
What does this workflow do?This will take your input image, crop/resize if needed to the ideal Cosmos render size, then automatically create an appropriate prompt for Cosmos to...
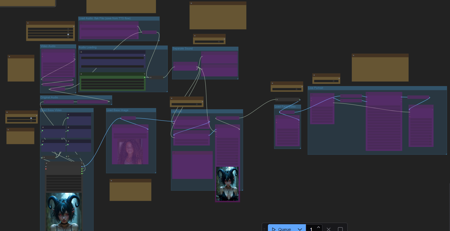
Audio To Video Lipsync (latentSync)版本v2 (ID: 1282333)
V2- added video audio loading- added original audio loading- added image base for sync- added live portrait extention for latentsync to LP Sync.V1.1-added .flak loading and a f...
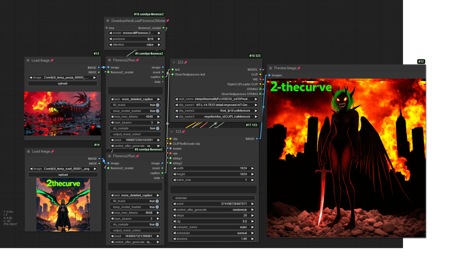
2N1 Workflow版本352N1 (ID: 1296686)
Upload two images, use florence to identify both pictures, combine the prompts of both images and make a new image
描述: This is the 2 pictures to form 1 pict...

Cosmos AUTOMATED Image to Video (I2V) - EnragedAntelope版本v1.1 (ID: 1299381)
What does this workflow do?This will take your input image, crop/resize if needed to the ideal Cosmos render size, then automatically create an appropriate prompt for Cosmos to...
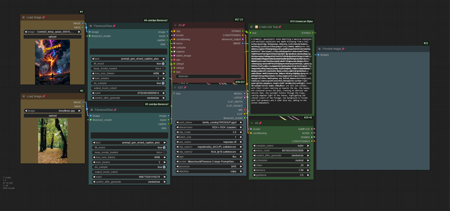
2N1 Workflow版本2N1PICFLUX(GGUF) (ID: 1291906)
Upload two images, use florence to identify both pictures, combine the prompts of both images and make a new image
描述: Added support for gguf Flux models
...

Sunvibe Danbooru Locations版本v2.0 (ID: 1285177)
This wildcard has 606 Danbooru Locations. Mileage will vary depending on checkpoint. Some are better at backgrounds than others.
描述: A few corrected under...

assDetailer, aDetailer model for butts, rears, pants, and panties版本v1-bbox (ID: 1300950)
v2-segmentation version:This is trained on YOLOv8-seg - the instance segmentation model. Basically it is more specific to the part it is targeting instead of a bounding box, it...
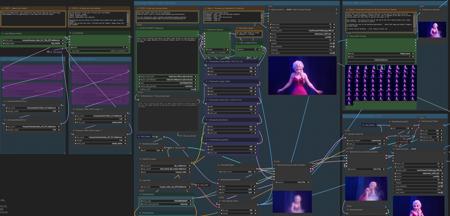
Hunyuan - YAW(Yet another workflow) - fast,t2v,v2v,multi-res,audio,preview pause,upscale,multi-lora, AIO, interpolate,teacache,options版本v4.1 (ID: 1284900)
Workflow highlights:Audio Generation - via MMaudio - Render Audio with your videosFAST preview generation with optional pausingPreview your videos in seconds before proceeding ...

7,000+ Sexy Prompts Snitched From Seljak版本2024.01.14 (ID: 1279957)
? Commissions, Training, Consultation - Flux, Pony, SDXL + Characters, Styles, Faces + ❤️ Support ? Discordℹ️ Original prompts were created by Seljak.ℹ️ I downloaded the prompt...
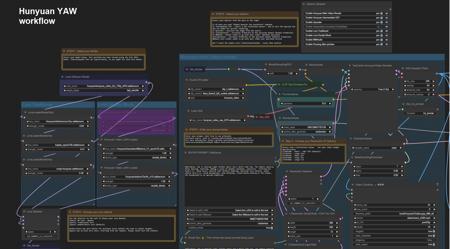
Hunyuan - YAW(Yet another workflow) - fast,t2v,v2v,multi-res,audio,preview pause,upscale,multi-lora, AIO, interpolate,teacache,options版本v4 (ID: 1280687)
Workflow highlights:Audio Generation - via MMaudio - Render Audio with your videosFAST preview generation with optional pausingPreview your videos in seconds before proceeding ...