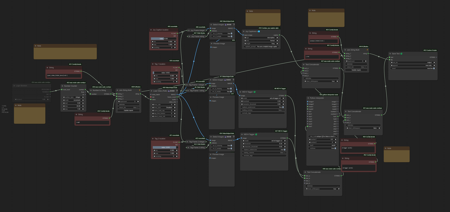
Preparing datasets for LoRAs can be a pain in the ass. Being lazy, I attempted to automate as much of the process as possible.
First, I have a workflow that extracts videos from a folder, and converts their fps to a target framerate of your choice (default 24 fps for Hunyuan). To do that, it takes the least common multiple "lcm" of the original and target fps (for example, for 30 and 24 it's 120), then it uses FILM to interpolate up to the lcm of the two numbers, and then it keeps only the frames it needs to go back down to the target fps. It's a bit overkill, but if you computer can handle it, it can save a bit of hassle.
I had to create a custom node for the math, here it is if the manager can't find it: https://github.com/EmilioPlumed/ComfyUI-Math.
Second, I have another workflow that captions the videos in a folder. I have it set up to use Joy Captioner alpha 2 to get a verbose description, and 2 wd14 taggers to get tags from different points. Each of the 3 captions have a slider to select from which portion of the video to extract the description or the tags. Then, it eliminates duplicate tags and puts the text together in a .txt file.
The workflows do require you to rename your files to be numbered consecutively.
描述:
训练词语:
名称: hunyuanVideoLora_captionVideos.zip
大小 (KB): 4
类型: Archive
Pickle 扫描结果: Success
Pickle 扫描信息: No Pickle imports
病毒扫描结果: Success





