LoRA Details
-
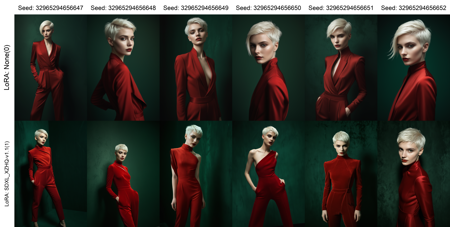
Test tune of ~17K images trained at 1024x1024 with buckets using captions from CogFlorence-2.2 at batch size 4 for 4 epochs.
-
All images were manually filtered to the best of my ability to avoid low quality/watermarks/AI/etc.
-
All images are originally at least 1024x1024 total pixels.
Reason for creating this LoRA
I wanted to throw some fairly high quality but "general use-case" images at a model to use as a base so it can be further trained on more specific tasks in the future.
描述:
This version does not contain much nudity, and may be biased towards women. I am working on increasing the dataset size and variety, and optimizing the training settings if needed.
There is a v1, but it was trained at batch size 1 for 1 epoch with the text encoder LR at half the amount v1.1 was trained at, so I don't feel it is worth publishing.
训练词语:
名称: SDXL_XZHQ-v1.1.safetensors
大小 (KB): 404885
类型: Model
Pickle 扫描结果: Success
Pickle 扫描信息: No Pickle imports
病毒扫描结果: Success