
This is my first distributed workflow for ComfyUI.
I had a simple idea to "re-image an existing image" type request. The idea was born, and this is it executed. In a nutshell this workflow take an image you give it, runs it through a image to text model, then re-combines what the image to text generates back into a prompt with T5xxl and ClipL along with any LoRa's or CSV Styles you want.
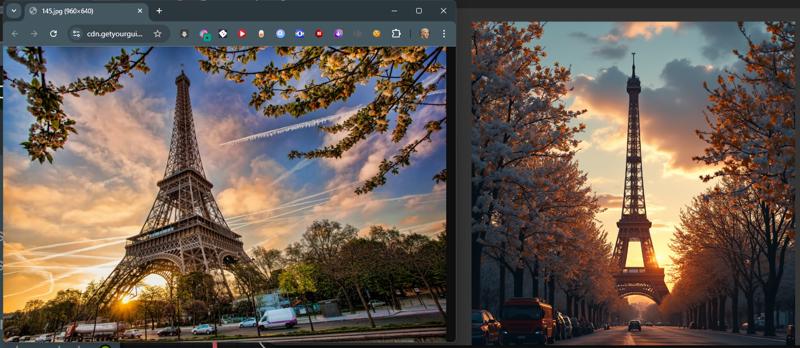
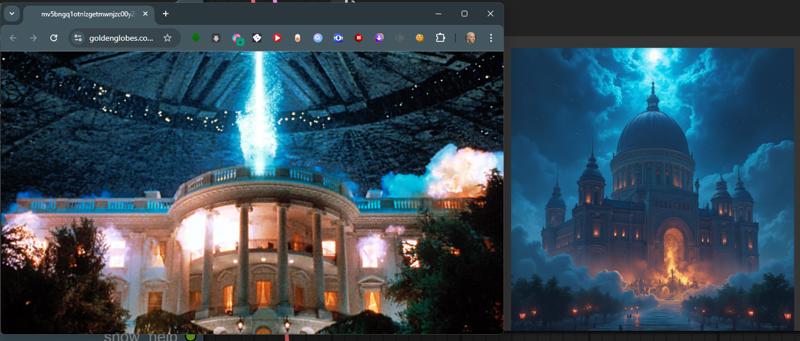
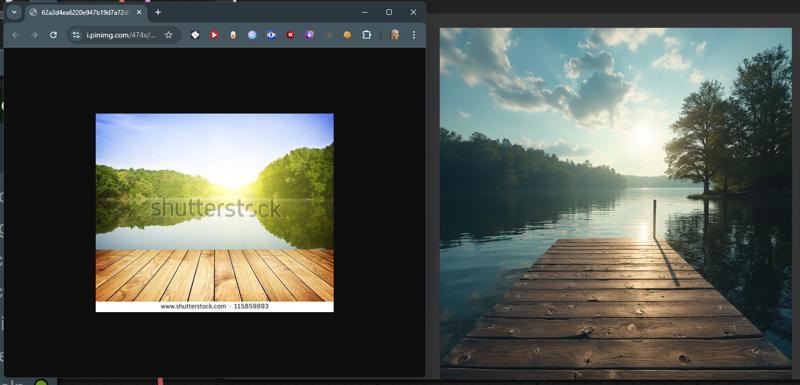
I have given some example pictures I am using the Flux GGUF models for this workflow but with a little editing you could alter it to fit any model. Some examples of what it will do. To the left the image directly from the internet. To the right, what the model did to "re-imagine" the that image.
Some examples of what it will do. To the left the image directly from the internet. To the right, what the model did to "re-imagine" the that image.
描述:
This is a smaller cut down version of the workflow not utilizing separate ClipL models. It has just one Image to Text model and doesn't have a separate ClipL pathing. It does use less than than Medium and Full, but still manages to work well.
训练词语:
名称: comfyuiReImagineImage_reimagineImageSmolV1.zip
大小 (KB): 7
类型: Archive
Pickle 扫描结果: Success
Pickle 扫描信息: No Pickle imports
病毒扫描结果: Success












