Please see our Quickstart Guide to Stable Diffusion 3.5 for all the latest info!
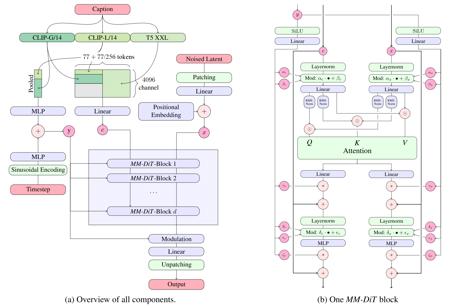
Stable Diffusion 3.5 Large is a Multimodal Diffusion Transformer (MMDiT) text-to-image model that features improved performance in image quality, typography, complex prompt understanding, and resource-efficiency.
Please note: This model is released under the Stability Community License. Visit Stability AI to learn or contact us for commercial licensing details.
Model Description
-
Developed by: Stability AI
-
Model type: MMDiT text-to-image generative model
-
Model Description: This model generates images based on text prompts. It is a Multimodal Diffusion Transformer that use three fixed, pretrained text encoders, and with QK-normalization to improve training stability.
License
-
Community License: Free for research, non-commercial, and commercial use for organizations or individuals with less than $1M in total annual revenue. More details can be found in the Community License Agreement. Read more at https://stability.ai/license.
-
For individuals and organizations with annual revenue above $1M: please contact us to get an Enterprise License.
Implementation Details
-
QK Normalization: Implements the QK normalization technique to improve training Stability.
-
Text Encoders:
-
CLIPs: OpenCLIP-ViT/G, CLIP-ViT/L, context length 77 tokens
-
T5: T5-xxl, context length 77/256 tokens at different stages of training
-
-
Training Data and Strategy:
This model was trained on a wide variety of data, including synthetic data and filtered publicly available data.
For more technical details of the original MMDiT architecture, please refer to the Research paper.
描述:
训练词语:
名称: stableDiffusion35_large.safetensors
大小 (KB): 16074589
类型: Model
Pickle 扫描结果: Success
Pickle 扫描信息: No Pickle imports
病毒扫描结果: Success