ATTENTION
DO NOT PAY FOR EA, IF YOU DON'T ACTUALLY KNOW HOW TO UTILZIE IT, PLEASE, I BEG YOU, THIS IS MEANT FOR EXPERIMENTATION PURPOSES
This is relatively VERY small training for CLIPs, done on dataset of ~13 thousands anime image+text pairs. If you are interested more about specifics, they will be at the bottom.
Do NOT expect extreme changes, as this is only smaller one of two clips, as im unable to tune BigG on my hardware. It takes 10 gigs to just load weights onto GPU, and im OOMing even at batch 1(which is useless for CLIP training, min is 2).
CLIP L Finetune
This is an experimental project for adapting existing CLIPs closer to anime. This prototype is very small, as CLIPs are supposed to be trained on millions of images at extreme batch sizes. While it does help in lots of places here and there, it will NOT significantly improve your model, especially without adapting U-Net to new CLIP output. In my tests it did improve output without such adaptation to some degree, but more tests needed.
It might break compatibility with existing loras for pony to a certain degree, but inconclusive on that one, did not test.
Why would you might want to use this?
It can improve stability and details in your images. Those images were produced on IsoliceXL, as i really can't cope with base Pony outputs, but i did perform tests on it too, and it improved composition and colors overall there too, and i will provide examples of that later.
Another disclosure: Isolice U-Net includes merge of model data of which was used in CLIP finetune. While it was not finetuned to align with new CLIP, it still might benefit more than other average model.
But TLDR is, it can affect output positively in general, from color tones to background/foreground separation, and down there are examples of it.
Eyes:

 (Yes, it produced more coherent eyes, while having a bit less area to work with. But of course, this is anecdotal and your experience may and will vary)
(Yes, it produced more coherent eyes, while having a bit less area to work with. But of course, this is anecdotal and your experience may and will vary)
hands:
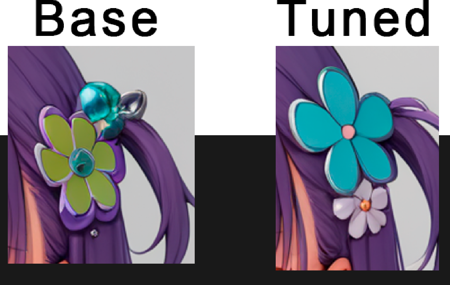
 Accessories:
Accessories:
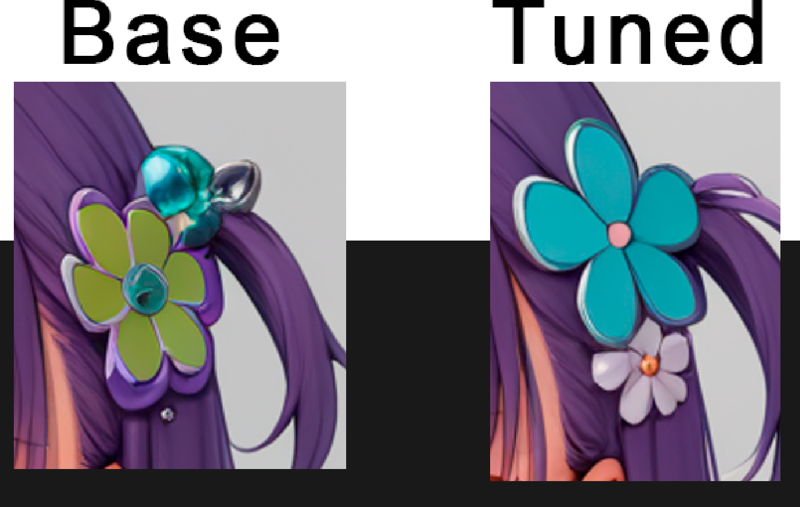 And anything related to small details possibly could be enhanced:
And anything related to small details possibly could be enhanced:


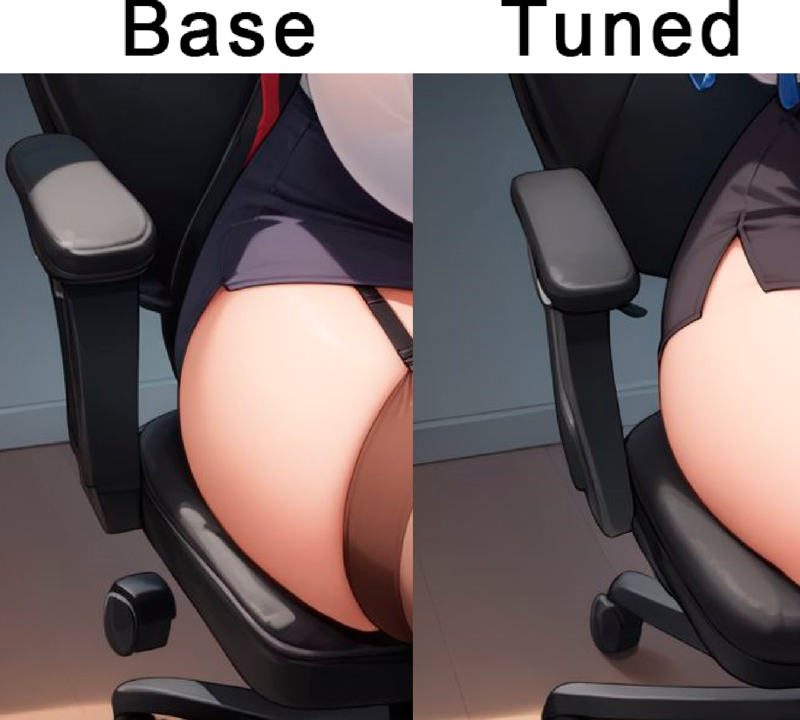 And full image on base Pony, which is most representative, as there was no other possible impurities introduced in merging vs base pony clip:
And full image on base Pony, which is most representative, as there was no other possible impurities introduced in merging vs base pony clip:

What should i look at?
In general, you will not see anything drastic. While swapping this CLIP can sometimes fix composition in more apparent way (i.e. incorrect character pose relative to background), such cases are fairly rare. This will affect mainly small details (that i adore ;-;)
Warnings and disclaimers
While i did not notice any failures in my tests, it is not guaranteed that this CLIP finetune is 100% good to go, as it is, after all, a prototype. I am still working on training loop of my own, as existing training solutions either overly complicated for me (like Openclip), or did not work, despite training seemingly working and keys staying normal (Happened with this repo but please try it and check for yourself, as i likely fucked something up, it could lead you to better results, as that guy has put a lot of effort in it)
To achieve full benefit, you need to train with new clip, not just put it into your model. By only putting it in, you will have modified CLIP, to which U-Net is not adapted to, which ould cause some issues, but i did not notice anything specific. While training with new CLIP, please do not train text encoder, as it is already finetuned to significant extent for anime, and you might break current weights by doing so, as from what i've seen, Kohya does not provide special treatment to text encoder training, which it seemingly requires.
How was it trained?
I used my own training loop, which i would not recommend(and not that i'll make it available anyway most likely)
Consider learning how to use OpenClip, or repo i mentioned above, that will be much more professional approach.
Dataset consisted of ~13000 richly tagged images.
Training was done for 35 epochs, after which i did not observe loss reduction and stopped it.
For CLIP training one of main parameters is batch size, as it needs to create contrastive pairs for loss computation, amount and quality of which directly affected by batch size.
In this training batch size was set to 128.
It was taking ~20 minutes per epoch, so total training time is 11 hours 40 minutes or so.
Plans and future
What future? I don't have hardware. I trained this on my poor 4060ti. You'll have to sponsor me to do more, lmao. I can't load up BigG even with all optimizations i have.
If you actually want to see BigG, or further L tuning happen and willing to sponsor it - contact me in discord(Anzhc).
It is possible that i will expand dataset in future, as i have images on hand, but they will need recaptioning, which is not very fast, and i have no intention of hanging my GPU for days at a time anymore, im tired.
描述:
Pony CLIP-L tuned for ~465k steps.
训练词语:
名称: prototypeCLIPLText_prototype.zip
大小 (KB): 408997
类型: Archive
Pickle 扫描结果: Success
Pickle 扫描信息: No Pickle imports
病毒扫描结果: Success