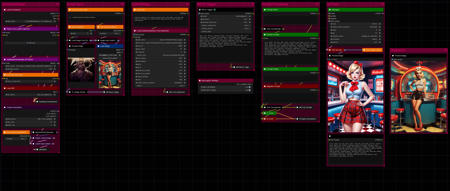
Hello there and thanks for checking out this workflow!
—Purpose—
This workflow makes use of a local LLM to interrogate and caption an input image, directly followed by a simple image generation based on the result.
Image → Text → Image
It is fun to see what some images result in, and also helpful for gaining prompt inspirations, due to the LLM's responses' likelihood of containing uncommon words, especially with odd, surrealist or abstract inputs.
The prompt generation is also optionally supported by WD 1.4 tagging, which in and of itself is powerful enough to get very accurate results, especially with vit-tagger-v3.
—Custom Nodes used—
All of which can be installed through the ComfyUI-Manager
If you encounter any nodes showing up red (failing to load), you can install the corresponding custom node packs through the 'Install Missing Custom Nodes' tab on the ComfyUI Manager as well.
—Thanks—
The workflow would not be possible as it is without these custom node packs. If you want to show your appreciation to the node creators, drop them a ⭐ on their github repos! Thank you!
Feel free to ask any questions, share improvements or suggestions in the comment section!
Also let me know if you encounter any confusing points I can elaborate on and focus on improving for the next update!
描述:
v1 — initial release
训练词语:
名称: comfyuiInterro_v1.zip
大小 (KB): 7
类型: Archive
Pickle 扫描结果: Success
Pickle 扫描信息: No Pickle imports
病毒扫描结果: Success





