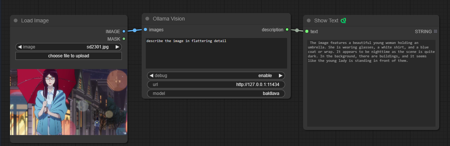
This is a ComfyUI workflow that uses Ollama to create a detailed image description. Simply download Ollama and install, it should open into the tray/background. Once Ollama is running in the background you can call it from CMD or terminal.
ollama run llava
? LLaVA is a novel end-to-end trained large multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding. Updated to version 1.6.
or
ollama run bakllava
BakLLaVA is a multimodal model consisting of the Mistral 7B base model augmented with the LLaVA architecture.
lets compare.
 Using this image.
Using this image.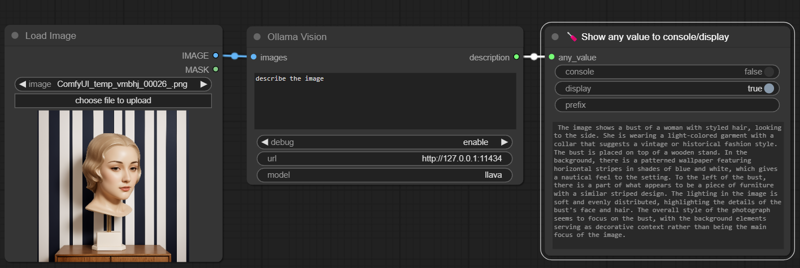 llava:
llava:
"The image shows a bust of a woman with styled hair, looking to the side. She is wearing a light-colored garment with a collar that suggests a vintage or historical fashion style. The bust is placed on top of a wooden stand. In the background, there is a patterned wallpaper featuring horizontal stripes in shades of blue and white, which gives a nautical feel to the setting. To the left of the bust, there is a part of what appears to be a piece of furniture with a similar striped design. The lighting in the image is soft and evenly distributed, highlighting the details of the bust's face and hair. The overall style of the photograph seems to focus on the bust, with the background elements serving as decorative context rather than being the main focus of the image."
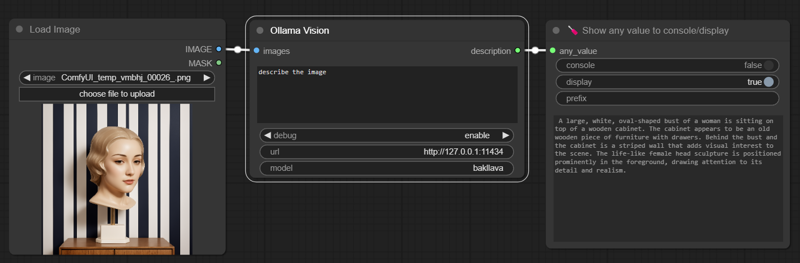 Bakllava:
Bakllava:
"A large, white, oval-shaped bust of a woman is sitting on top of a wooden cabinet. The cabinet appears to be an old wooden piece of furniture with drawers. Behind the bust and the cabinet is a striped wall that adds visual interest to the scene. The life-like female head sculpture is positioned prominently in the foreground, drawing attention to its detail and realism."
In my biased unhumble opinion Bakllava is more concise, hallucinates less, and is overall the better model.
However Llava gets a couple key features of the image that Bakllava misses such as the nautical feel and soft lighting.
If you need zero shot reliability, at a glance Bakllava would be the go to choice. If you plan to use the output yourself it could make sense to run both and get those extra observations copied over into a more complete description.
So you choose to install one or both of the models by running them once with Ollama, once they install you can test them out right there in the console or just close that.
To Load the Json into ComfyUI you need some custom nodes
Git clone
pythongosssss/ComfyUI-Custom-Scripts
and
stavsap/comfyui-ollama
Into the custom nodes folder of your ComfyUi install.
If you don't have those, you can install those, git or ComfyUI-Manager
Good luck, and pleasant visions.
描述:
训练词语:
名称: llavavision_v11.zip
大小 (KB): 1
类型: Archive
Pickle 扫描结果: Success
Pickle 扫描信息: No Pickle imports
病毒扫描结果: Success





